Novotek DataOps Hackaton – Dag 1
Hackaton dagtopics | 13 maart
- Installeren Highbyte
- Merge data
- Data storage
Kick-off Hackaton met 16 engineers!
Wat krijg je als je 16 automation engineers uit 8 verschillende landen bij elkaar zet om verschillende challenges uit te voeren op het gebied van data operations? Precies, de eerste Novotek DataOps Hackaton. We krijgen steeds meer vragen van klanten hoe ze om moeten gaan met de alsmaar groter wordende hoeveelheid data die uit hun productieproces komt. Aan de andere kant komen er steeds nieuwere technieken beschikbaar via onze leveranciers om hier op een gestructureerde manier mee om te gaan, zoals MQTT, Sparkplug-B en Docker. Hoogste tijd om hier eens in te duiken.
Lees de Insight: MQTT wat kun je er mee?
Docker installeren
We beginnen de dag met het voorbereiden van onze systemen op al die nieuwe technieken, te beginnen met Docker. Het installeren van een nieuw product wordt hiermee wel erg eenvoudig. Waar je je vroeger nog door allerlei opties en next->next->next moest worstelen is nu het kopiëren van een Docker-image voldoende om het product geïnstalleerd te krijgen. Vervolgens typ je “Docker run” en klaar is Kees.
Van OPC naar MQTT
Op deze manier is een product als HighByte in enkele minuten te installeren. De configuratie verloopt vervolgens via een browser. HighByte is een product om data binnen te halen via OPC, te modelleren en beschikbaar te stellen middels MQTT. Het eerste wat dan ook dient te gebeuren is een koppeling maken met de lokale Kepware OPC UA server. Op het moment dat je het juiste certificaat gekoppeld hebt is dat een fluitje van een cent. Vervolgens heb je middels browsing toegang tot al je procesdata.
- Lees de insight: Waarom zou je data modelleren?
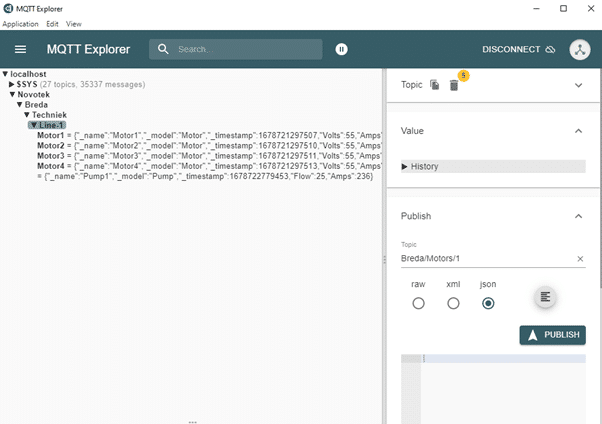
Aan de andere kant dien je een verbinding te maken met een MQTT broker, die vervolgens de data publiceert. In de laatste versie 3.0 van HighByte zit al een MQTT broker dus dat is simpel. Met de tool MQTT Explorer kun je vervolgens zien wat er gepubliceerd wordt. Nu de verbindingen gemaakt zijn kunnen we aan het modelleren. HighByte biedt een flexibele manier om data vorm te geven zoals de consumers van die data dat graag zouden zien. Heeft een pomp bijvoorbeeld drie eigenschappen waaronder de snelheid, temperatuur en stroomverbruik dan maak je een object met die drie attributen. Vervolgens kun je heel eenvoudig de brondata aan deze eigenschappen koppelen.
Als laatste stap creëer je een flow waarin je aangeeft hoe de data van bron naar target gestuurd wordt, wanneer en hoe vaak. Zo kun je meerdere databronnen aan meerdere brokers koppelen. Morgen gaan we verder met het aggregeren, bufferen en vervolgens opslaan van data.